



一,前言
MySQL索引的建立对于 MySQL 的高效运行是很重要的,索引可以大大提高 MySQL 的检索速度。
索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
过多的使用索引将会造成滥用,因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE 和 DELETE。因为更新表时,MySQL 不仅要保存数据,还要保存一下索引文件。
二,聚集索引和非聚集索引
根据索引的存储方式来划分,索引可以分为聚簇索引和非聚簇索引。聚簇索引的特点是叶子节点包含了完整的记录行,而非聚簇索引的叶子节点只有索引字段和主键 ID。非聚簇索引中因为不含有完整的数据信息,查找完整的数据记录需要回表,所以一次查询操作实际上要做两次索引查询。
聚集索引
聚集索引定义了表中数据的物理存储顺序,索引顺序和物理顺序一致。一个表只能有一个聚集索引,Innodb 的存储索引是基于 B+tree 聚集索引,存储了索引,同时叶子节点存储行记录。
聚集索引又是以物理磁盘顺序来存储的,自增主键会把数据自动向后插入,避免了插入过程中的聚集索引排序问题。
如何判断哪个主键是聚集索引?
- 如果一个主键被定义了,那么这个主键就是作为聚集索引。
- 如果没有主键被定义,那么该表的第一个唯一非空索引被作为聚集索引。
- 如果没有主键也没有合适的唯一索引,那么innodb内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键是一个6个字节的列,改列的值会随着数据的插入自增。
非聚簇索引
除了聚簇索引的其他索引都是非聚簇索引,叶节点指向表中的聚集索引的id,记录的物理顺序与逻辑顺序没有必然的联系。 非聚集索引访问数据总是需要二次查找。
- 叶子节点并不包含行记录的全部数据,叶子节点除了包含键值外,还包含了相应行数据的聚簇索引键。
- 不影响数据在聚簇索引中的组织,所以一张表可以有多个非聚集索引。
三,覆盖索引
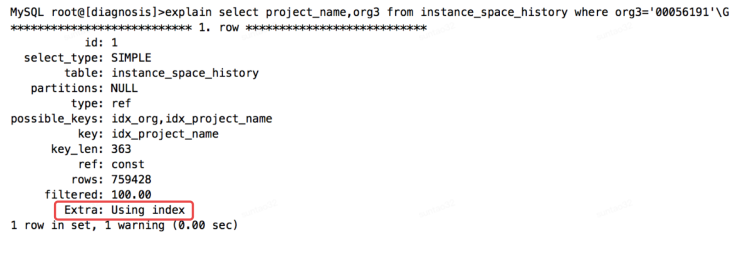
如果一个索引包含所有需要查询的字段的值,不需要回表操作,可以称之为实现了索引覆盖。
从执行计划看,Extra 的信息为 using index ,即用到了索引覆盖。
覆盖索引就实现了从非聚簇索引中直接获取数据,所以效率会提升。
四,索引类型
索引的几种类型分别是普通索引、唯一索引、聚集索引、主键索引、全文索引几种。
-
唯一索引 UNIQUE:表示唯一的,不允许重复的索引,如果该字段信息保证不会重复例如身份证号用作索引时,可设置为unique;
-
主键索引 PRIMARY:唯一且不能为空;一张表只能有一个主键索引;
-
复合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并;
-
普通索引 INDEX:它的结构主要以B+树和哈希索引为主,主要是对数据表中的数据进行精确查找;
-
全文索引 FULLTEXT:表示 全文搜索的索引。 FULLTEXT 用于搜索很长一篇文章的时候,效果最好。用在比较短的文本,如果就一两行字的,普通的 INDEX 也可以。
五,索引方法
MySQL目前主要有以下几种索引方法:B-Tree,Hash;
B-Tree
B-Tree 是最常见的索引类型,所有值(被索引的列)都是排过序的,每个叶节点到跟节点距离相等。所以B-Tree适合用来查找某一范围内的数据,而且可以直接支持数据排序(ORDER BY)
B-Tree 在 MyISAM 里的形式和 Innodb 稍有不同:
MyISAM表数据文件和索引文件是分离的,索引文件仅保存数据记录的磁盘地址;
InnoDB表数据文件本身就是主索引,叶节点data域保存了完整的数据记录;
Hash索引
-
仅支持"=","IN"和"<=>"精确查询,不能使用范围查询:
由于Hash索引比较的是进行 Hash 运算之后的 Hash 值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的 Hash 算法处理之后的Hash; -
不支持排序:
由于 Hash 索引中存放的是经过Hash计算之后的 Hash 值,而且 Hash 值的大小关系并不一定和 Hash 运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算; -
在任何时候都不能避免表扫描:
由于Hash索引比较的是进行Hash运算之后的Hash值,所以即使取满足某个Hash键值的数据的记录条数,也无法从Hash索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果; -
检索效率高,索引的检索可以一次定位,不像B-Tree索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以Hash索引的查询效率要远高于B-Tree索引;
评论区