



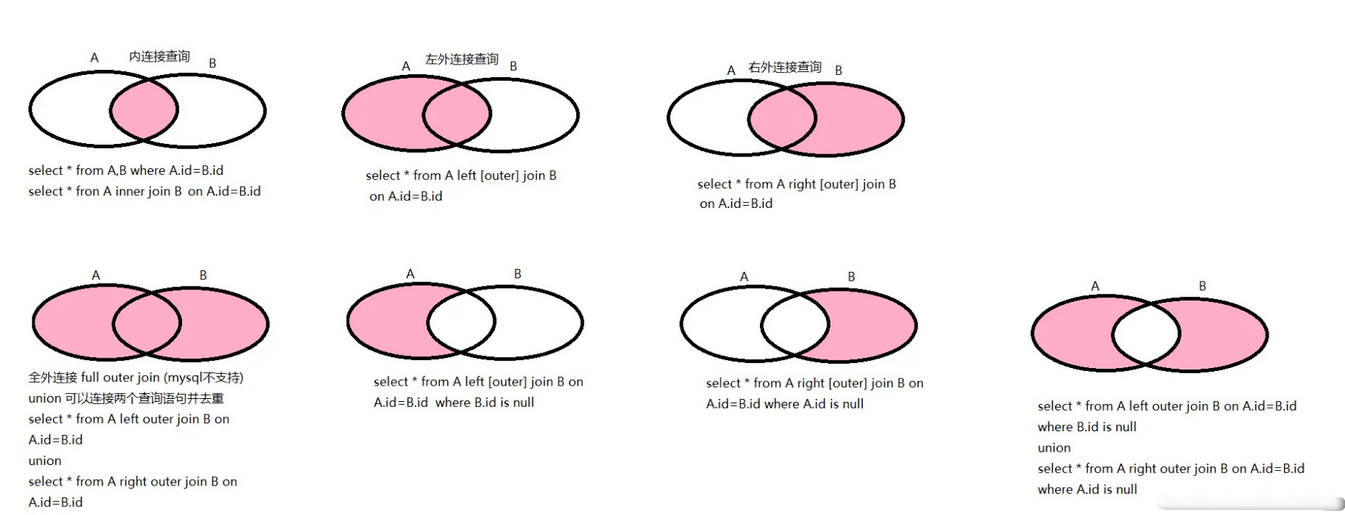
一,内连接和外连接
内连接和外连接的根本区别就是在驱动表中的记录不符合 ON ⼦句中的连接条件时会不会把该记录加⼊到最后的结果集。
- 对于内连接的两个表,驱动表中的记录在被驱动表中找不到匹配的记录,该记录不会加⼊到最后的结果集,这里ON⼦句和 where ⼦句是等价的,所以内连接中不要求强制写明 ON ⼦句。
- 对于外连接的两个表,驱动表中的记录即使在被驱动表中没有匹配的记录,也仍然需要加⼊到结集,外连接中必须使⽤ON⼦句来指出连接条件。
where ⼦句中的过滤条件就是我们平时⻅的那种,不论是内连接还是外连接,凡是不符合WHERE⼦句中的过滤条件的记录都不会被加⼊最后的结果集。 ⼀般情况下,我们都把只涉及单表的过滤条件放到 where ⼦句中,把涉及两表的过滤条件都放到 ON ⼦句中,我们也⼀般把放到ON⼦句中的过滤条件也称之为连接条件。
注意,在外连接查询中,驱动表过滤必须放where条件中,被驱动表过滤放on条件中,这样结果才能不多不少,刚刚好。
二,连接的原理
2.1,嵌套循环连接(Nested-Loop Join)
对于两表连接来说,驱动表只会被访问⼀遍,但被驱动表却要被访问到好多遍,具体访问⼏遍取决于对驱动表执⾏单表查询后的结果集中的记录条数。对于内连接来说,选取哪个表为驱动表都没关系,⽽外连接的驱动表是固定的,也就是说左连接的驱动表就是左边的那个表,右连接的 驱动表就是右边的那个表。我们上边已经⼤致介绍过t1表和t2表执⾏内连接查询的⼤致过程,我们温习⼀下:
- 步骤1:选取驱动表,使⽤与驱动表相关的过滤条件,选取代价最低的单表访问⽅法来执⾏对驱动表的单表查询。
- 步骤2:对上⼀步骤中查询驱动表得到的结果集中每⼀条记录,都分别到被驱动表中查找匹配的记录。
流程图如下:
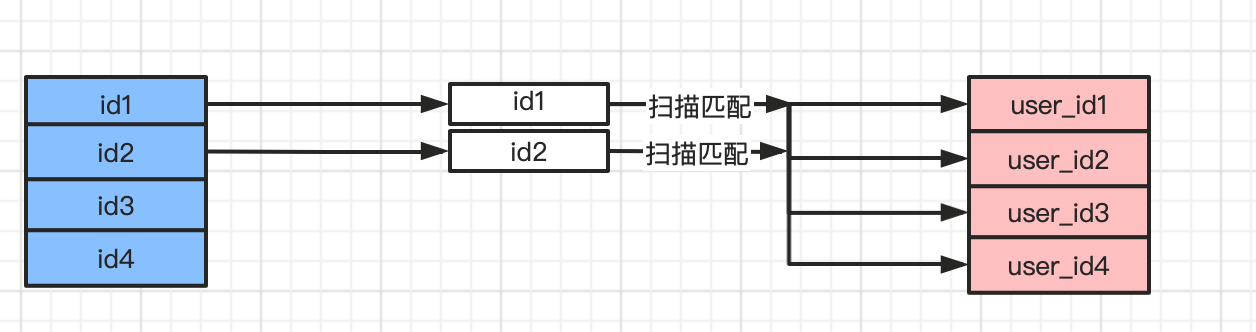
如果有3个表进⾏连接的话,那么步骤2中得到的结果集就像是新的驱动表,然后第三个表就成为了被驱动表,重复上边过程,也就是步骤2中得到的结果集中的每⼀条记录都需要到t3表中找⼀找有没有匹配的记录。
这个过程就像是⼀个嵌套的循环,所以这种驱动表只访问⼀次,但被驱动表却可能被多次访问,访问次数取决于对驱动表执⾏单表查询后的结果集中的记录条数的连接执⾏⽅式称之为嵌套循环连接,这是最简单,也是最笨拙的⼀种连接查询算法。
2.2,索引嵌套循环连接(Index Nested-Loop Join)
索引嵌套循环(Index Nested-Loop Join)是使用索引减少扫描的次数来提高效率的,所以要求非驱动表上必须有索引才行。
在查询的时候,驱动表会根据关联字段的索引进行查询,当索引上找到符合的值,才会进行回表查询。如果非驱动表的关联字段是主键的话,查询效率会非常高,因为主键索引结构的叶子结点包含了完整的行数据(InnoDB);
如果不是主键,每次匹配到索引后都需要进行一次回表查询,性能肯定弱于主键的查询。
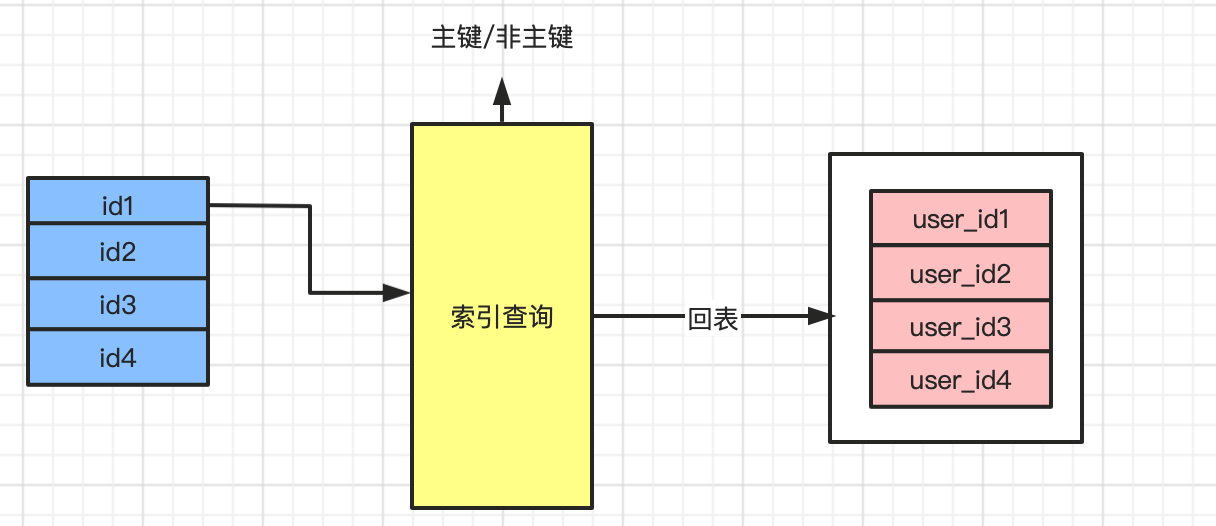
上图中的索引查询之后不一定会回表,什么情况下会回表,这个要看索引查询到的字段能不能满足查询需要的字段。
2.3,基于块的嵌套循环连接(Block Nested-Loop Join)
如果存在索引,那么会使用index的方式进行join,如果join的列没有索引,被驱动表要扫描的次数太多了,每次访问被驱动表,其表中的记录都会被加载到内存中,然后再从驱动表中取一条与其匹配,匹配结束后清除内存,然后再从驱动表中加载一条记录 然后把被驱动表的记录在加载到内存匹配,这样周而复始,大大增加了IO的次数。为了减少被驱动表的IO次数,就出现了Block Nested-Loop Join的方式。
设计 MySQL 的⼤叔提出了⼀个 join buffer 的概念,join buffer 就是执⾏连接查询前申请的⼀块固定⼤小的内存,先把若⼲条驱动表结果集中的记录装在这个 join buffer 中,然后开始扫描被驱动表,每⼀条被驱动表的记录⼀次性和 join buffer 中的多条驱动 表记录做匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著减少被驱动表的 I/O 代价。
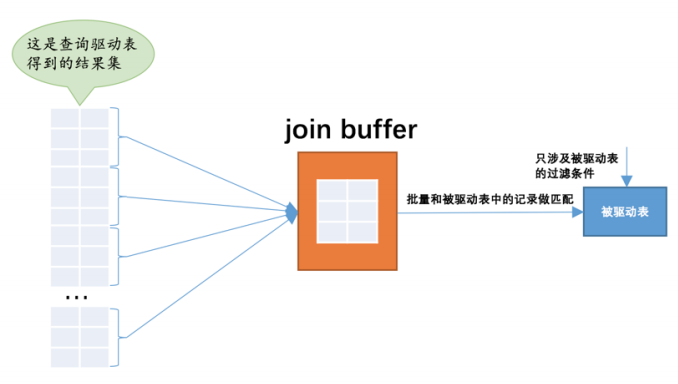
最好的情况是 join buffer ⾜够⼤,能容纳驱动表结果集中的所有记录,这样只需要访问⼀次被驱动表就可以完成连接操作了。这种加⼊ 了join buffer的嵌套循环连接算法称为基于块的嵌套连接算法。
这个 join buffer 的⼤⼩是可以通过启动参数或者系统变量 join_buffer_size 进⾏配置,默认⼤⼩为 262144 字节(也就是256KB),最⼩可以设置为 128 字节。
另外需要注意的是,驱动表的记录并不是所有列都会被放到 join buffer 中,只有查询列表中的列和过滤条件中的列才会被放到 join buffer 中,所以再次提 醒我们,最好不要把 * 作为查询列表,只需要把我们关⼼的列放到查询列表就好了,这样还可以在 join buffer 中放置更多的记录呢哈。
三,总结
不论是Index Nested-Loop Join 还是 Block Nested-Loop Join 都是在Simple Nested-Loop Join的算法的基础上进行优化,这里 Index Nested-Loop Join 和 Nested-Loop Join 算法是分别对 Join 过程中循环匹配次数和 IO 次数两个角度进行优化。
Index Nested-Loop Join 是通过索引的机制减少内层表的循环匹配次数达到优化效果,而Block Nested-Loop Join 是通过一次缓存多条数据批量匹配的方式来减少内层表的扫表IO次数。
当然,对于优化被驱动表的查询来说,最好是为被驱动表加上效率⾼的索引,如果实在不能使⽤索引,并且⾃⼰的机器的内存也⽐较⼤可以尝试调⼤ join_buffer_size 的值来对连接查询进⾏优化。
通过 理解 join 的算法原理我们可以得出以下表连接查询的优化思路。
1、永远用小结果集驱动大结果集 ,其本质就是减少外层循环的数据数量;
2、为匹配的条件增加索引,减少驱动表的循环匹配次数;
3、增大 join buffer size 的大小,一次缓存的数据越多,那么内层包的扫表次数就越少;
4、减少不必要的字段查询,字段越少,join buffer 所缓存的数据就越多。
评论区