



一,前言
如今大型的 IT 系统中,都会使用分布式的方式,同时会有非常多的中间件,如 redis、消息队列、大数据存储等,但是实际核心的数据存储依然是存储在数据库,作为使用最广泛的数据库,如何将 mysql 的数据与中间件的数据进行同步,既能确保数据的一致性、及时性,也能做到代码无侵入的方式呢 ?
如果有这样的一个需求,数据修改后,需要及时将 mysql 中的数据更新到 MongoDB,我们会怎么进行实呢?
二,Canal 是什么
canal 是阿里巴巴的一个开源项目,基于java实现,整体已经在很多大型的互联网项目生产环境中使用,包括阿里、美团等都有广泛的应用,是一个非常成熟的数据库同步方案,基础的使用只需要进行简单的配置即可。Canal的部署也是支持集群的,需要配合ZooKeeper进行集群管理。
官网的介绍:
canal,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
canal 的工作原理就是把自己伪装成 MySQL slave,模拟 MySQL slave 的交互协议向 MySQL Mater 发送 dump 协议,MySQL mater 收到 canal 发送过来的 dump 请求,开始推送 binary log 给 canal,然后 canal 解析 binary log,再发送到存储目的地,比如 MySQL,Kafka,Elastic Search 等等。
实际项目我们是配置 MQ 模式,canal 会把数据发送到 MQ 的 topic 中,由对应消费者进行处理。
以下是 canal 原理图:
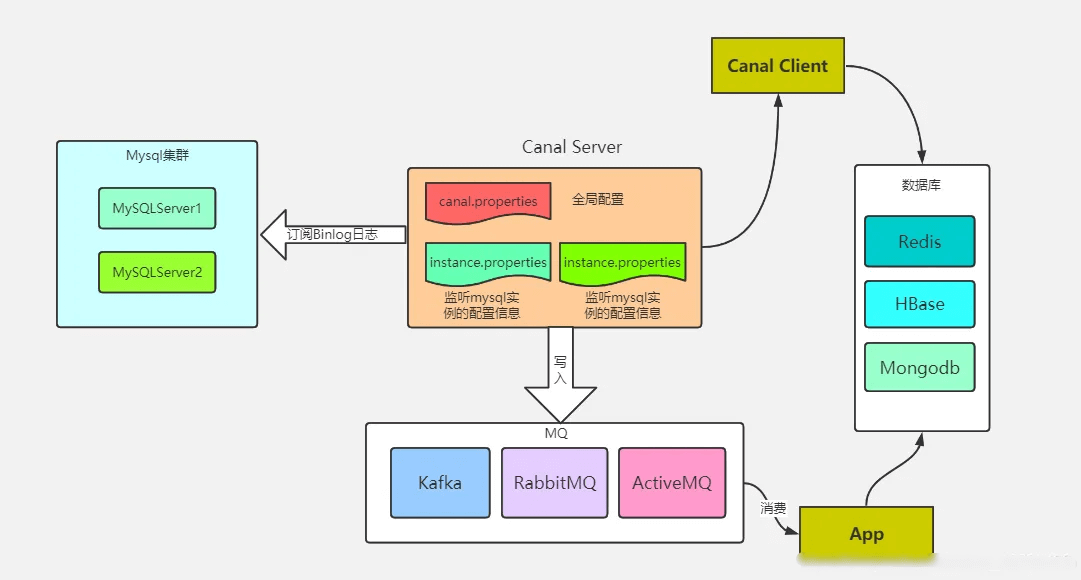
三,canal 实战
3.1,场景
MySQL 部分表的数据变动需要实时同步 MongoDB 中,达到数据的一致性。
3.2,搭建
3.2.1 MySQL 设置
目的:开启 Binlog,生成 Canal 账号。
编辑 MySQL 配置文件:
$ vim /etc/my.cnf
修改以下配置:
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 #配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
重启 MySQL:
$ service mysqld restart
MySQL 检查 Binlog 开启状态:
$ show variables like 'log_%';
看到 log_bin on表示已开启。
查看 Binlog 当前日志:
$ show master status;
生成 Canal 账号:
$ CREATE USER canal的账号 IDENTIFIED BY 'canal的密码';
$ GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
$ FLUSH PRIVILEGES;
3.2.2,Canal 设置
1,下载:
下载 deployer,选择合适版本,如 canal.deployer-1.1.6.tar.gz。
2,上传到服务器:
将压缩包上传的服务器 /usr/local/canal 目录下,并解压:
$ tar zxvf canal.deployer-1.1.6.tar.gz
3,设置实例参数:
$ vim conf/example/instance.properties
修改以下配置:
# position info,需要改成自己的数据库信息
canal.instance.master.address = mysql的ip:mysql端口
# username/password,需要改成自己的数据库信息
canal.instance.dbUsername = 在MySQL中创建的Canal账号
canal.instance.dbPassword = 在MySQL中创建的Canal密码
canal.instance.filter.regex=要监听的表,如 database.table
canal.instance.filter.field=要监听表的字段,如 database.table:userId/niceName/phone
# MQ主题
canal.mq.topic=canal_routing_key
4,设置过滤日志参数:
$ vim conf/canal.properties
修改以下配置:
#需要过滤掉ddl、dcl日志,否则都会传输到应用服务中(非常多日志)
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = true
canal.instance.filter.query.dml = true
canal.instance.filter.query.ddl = true
canal.instance.filter.table.error = true
canal.instance.filter.transaction.entry = true
#不过滤增删改
canal.instance.filter.rows = false
canal.instance.filter.dml.insert = false
canal.instance.filter.dml.update = false
canal.instance.filter.dml.delete = false
5,设置MQ参数:
$ vim conf/canal.properties
修改以下配置:
canal.serverMode = rabbitMQ
rabbitmq.host = 自己MQ的ip
rabbitmq.virtual.host = 自己MQ的虚拟主机
rabbitmq.exchange = canal.exchange
rabbitmq.username = 自己MQ的用户名
rabbitmq.password = 自己MQ密码
6,启动:
$ sh bin/startup.sh
7,查看日志
$ tail -f logs/canal/canal.log
$ tail -f logs/example/example.log
3.2.3,业务处理
通过 MQ 接收消息并消费:
@RabbitListener(bindings = {
@QueueBinding(
value = @Queue(value = AmqpExchange.CANAL_QUEUE, durable = "true"),
exchange = @Exchange(value = AmqpExchange.CANAL_EXCHANGE),
key = AmqpExchange.CANAL_ROUTING_KEY
)
} )
public void handleCanalDataChange(byte[] message) {
String realMsg = null;
try {
realMsg = new String(message, "utf-8");
JSONObject msg = JSON.parseObject(realMsg);
String database = msg.getString("database");
if(SynEnums.foreachEnum(database) == null){
return;
}
log.info("[canal] 接收消息: {}", realMsg);
//表名
String table=msg.getString("table");
//操作类型
String type=msg.getString("type");
// 业务处理...
} catch (Exception e) {
log.error("接收canal异常,数据: {}", realMsg);
}
}
四,总结
canal 的好处在于对业务代码没有侵入,因为是基于监听 binlog 日志去进行同步数据的,实时性也能做到准实时,其实是很多企业一种比较常见的数据同步的方案。
实际项目我们是配置 MQ 模式,canal 会把数据发送到 MQ 的 topic 中,由消费者进行处理。
评论区