



一,java多线程池的支持——ThreadPoolExecutor
java的线程池支持主要通过ThreadPoolExecutor来实现,我们使用的ExecutorService的各种线程池策略都是基于ThreadPoolExecutor实现的,所以ThreadPoolExecutor十分重要。
线程池的创建:

具体解释一下上述参数:
①corePoolSize 核心线程池大小:
核心池的大小,如果调用了prestartAllCoreThreads()或者prestartCoreThread()方法,会直接预先创建corePoolSize的线程,否则当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中;这样做的好处是,如果任务量很小,那么甚至就不需要缓存任务,corePoolSize的线程就可以应对;
②maximumPoolSize 线程池最大容量大小:
线程池最大线程数,表示在线程池中最多能创建多少个线程,如果运行中的线程超过了这个数字,那么相当于线程池已满,新来的任务会使用RejectedExecutionHandler 进行处理;
③keepAliveTime 线程池空闲时,线程存活的时间:
表示线程没有任务执行时最多保持多久时间会终止,然后线程池的数目维持在corePoolSize 大小;
④TimeUnit 时间单位:
参数keepAliveTime的时间单位;
⑤ThreadFactory 线程工厂:
主要用来创建线程,比如可以指定线程的名字;
⑥BlockingQueue任务队列 一个阻塞队列:
用来存储等待执行的任务,如果当前对线程的需求超过了corePoolSize大小,才会放在这里;
⑦RejectedExecutionHandler 线程拒绝策略:
如果线程池已满,执行拒绝策略。
二,线程池处理的流程
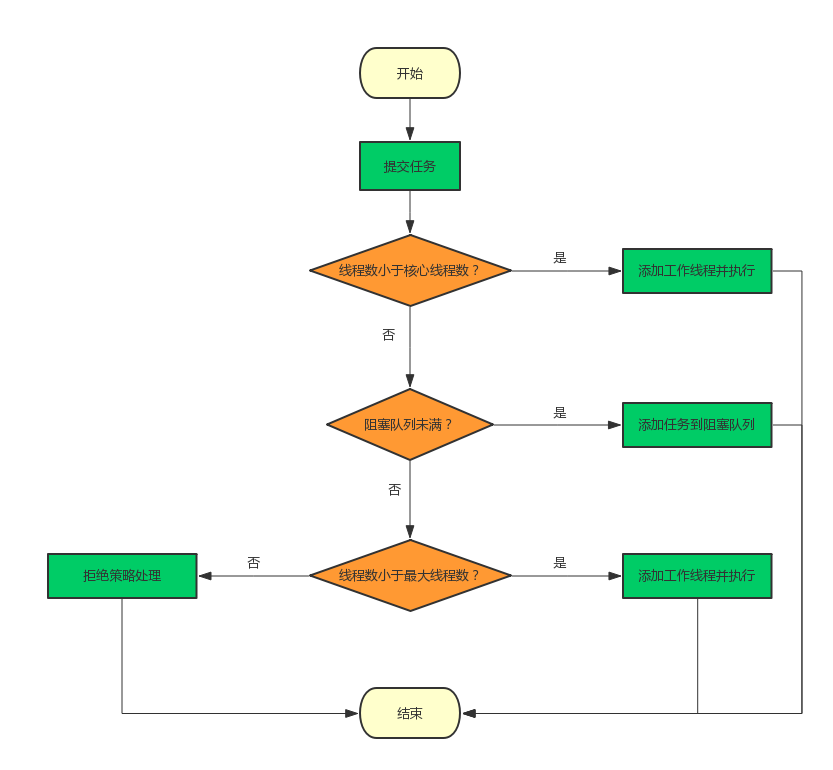
① 先判断线程池中的核心线程们是否空闲,如果空闲,就把这个新的任务指派给某一个空闲线程去执行。如果没有空闲,并且当前线程池中的核心线程数还小于 corePoolSize,那就通过 addWorker() 再创建一个核心线程。
② 如果线程池的线程数已经达到核心线程数,并且这些线程都繁忙,workQueue.offer() 方法就把这个新来的任务放到等待队列中去。
③ 如果等待队列又满了,那么查看一下当前线程数是否到达 maximumPoolSize,如果还未到达,就继续创建线程。如果已经到达了,就交给 RejectedExecutionHandler 来决定怎么处理这个任务(拒绝策略)。
关键代码:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
三,拒绝策略 RejectedExecutionHandler

①**AbortPolicy**: (默认)丢弃任务并抛出RejectedExecutionException异常。
②**CallerRunsPolicy**: 由调用线程(提交任务的线程,比如main主线程)直接执行此任务。
③**DiscardOledestPolicy**:丢弃队列最前面的任务,然后重新提交被拒绝的任务。
④**DiscardPolicy**:丢弃任务,但是不抛出异常。
以上策略都实现了RejectedExecutionHandler接口。当然,可自定义拒绝策略。
下面看看CallerRunsPolicy代码:
public static class CallerRunsPolicy implements RejectedExecutionHandler {
//Creates a {@code CallerRunsPolicy}.
public **CallerRunsPolicy**() { }
//Executes task r in the caller's thread, unless the executor
// has been shut down, in which case the task is discarded.
//@param r the runnable task requested to be executed
// @param e the executor attempting to execute this task
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
** r.run();**
}
}
}
如果线程池和队列都满了,那做为调用者,就自己去执行 r.run(),有帮于减轻线程池的压力。
四,介绍几种线程池
①**newFixedThreadPool**(): 返回一个固定线程数量的线程池。等待队列Queue使用LinkedBlockingQueue无界队列实现。
②**newSingleThreadExecutor**(): 返回只有一个线程的线程池。它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。等待队列Queue使用LinkedBlockingQueue实现。
③**newCacheThreadPool**(): 创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。Queue使用SynchronousQueue实现。
④**newScheduledThreadPool**(): 返回一个ScheduledExecutorService对象,可以根据时间需要对线程进行调度。
方法:schedule():在给定时间,对任务进行一次调度。
scheduleAtFixedRate()
任务调度的频率的一定的。
schedulWithFixedDelay()
创建并执行一个周期性任务。
五,等待队列分类
WorkQueue指被提交但未执行的任务队列,是一个BlockingQueue接口的对象,仅存放Runnable对象。按照功能分类:
①直接提交的队列(SynchronousQueue:容量大小为0)
提交的任务不会被真是保存,而总是将新任务提交给线程执行,如果没有空闲的线程,则尝试创建新的线程,如果线程数量已经达到最大值,则执行拒绝策略。
②有界任务队列(ArrayBlockingQueue)
仅当在任务队列满时,才可能将线程数提升到 corePoolSize 以上;若总线程数大于maxmumPoolSize,则执行拒绝策略
③无界任务队列(LinkedBlockingQueue)
④优先任务队列(PriorityBlockingQueue:)
带有执行优先级的队列。
六,工作线程和等待队列
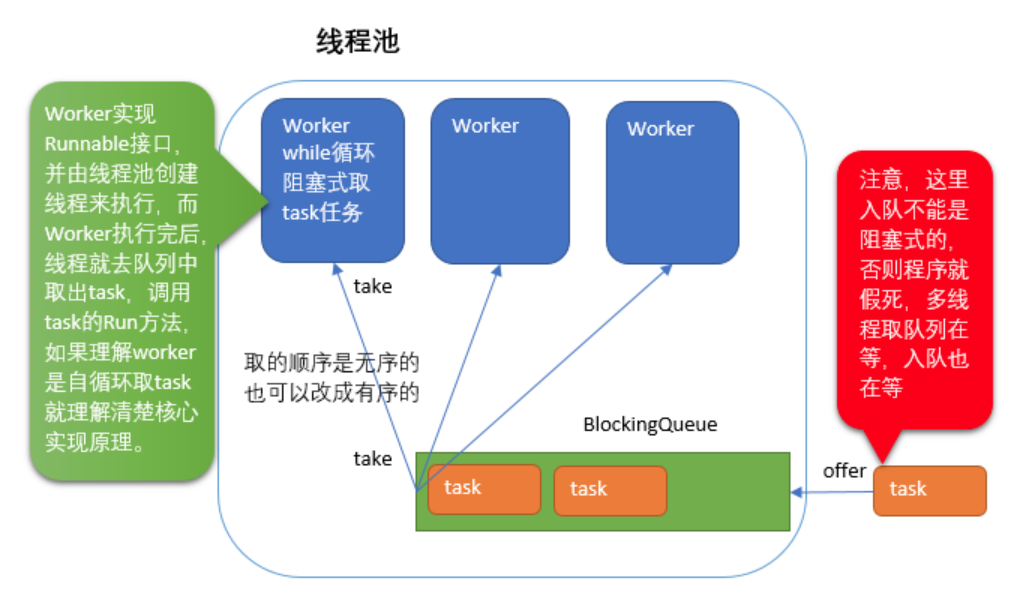
工作线程里的逻辑都封装在Worker这个内部类里了。代码如下所示:
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
/** If pool is stopping, ensure thread is interrupted;
if not, ensure thread is not interrupted. This
requires a recheck in second case to deal with
shutdownNow race while clearing interrupt**/
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
有几个地方要注意的,第一,我们可以使用beforeExecute和afterExecute这两个方法去监控任务的执行情况,这些方法在ThreadPoolExecutor里都是空方法,可以重写这些方法来实现线程池的监控。
第二,就是线程的逻辑是不断地执行一个循环,去调用 getTask 方法来获得任务:
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) { //**相对while(true),指令更少,不占用寄存器,而且没有判断跳转,效率更高。**
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN && (rs >= STOP || **workQueue.isEmpty()**)) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// Are workers subject to culling?
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
这个方法的核心点在于workQueue.poll,workQueue的类型是:
private final BlockingQueue<Runnable> workQueue;
这是一个阻塞队列!!这就意味着,如果某一个线程试图从这个队列中取数据,而这个队列里没有数据的时候,线程就会进入休眠了。
至于前边的那些逻辑,加加减减的,并不重要,感兴趣的可以自己查看这个方法的注释,总而言之,就是返回一个null,让worker线程退出。所以,getTask里能返回 null 的分支都是满足线程退出条件的。
评论区