



一,发现服务器内存占用过高
巡检中发现服务器内存占用过高,接近 80%,进入服务器查看。
#按 k 查看
# free
#按 m 查看
# free -m

total:总计物理内存的大小
used:已使用多大
free:可用有多少
Shared:多个进程共享的内存总额
Buffers/cached:磁盘缓存的大小
所以空闲内存 = free + buffers + cached = total - used
二,top
# top -c
# 然后shift + m 按照内存占用排序

可以看到,java 进程 19677 就占用了 24.7% ,8G 左右的内存。
三,查看该进程日志打印文件是否过大
进入该进程对应的服务目录,查看对应的日志打印文件是否过大而占用内存。
$ du -sh *
如果文件太大,置空该日志打印文件:
$ > xxx.log
四,定位线程问题
ps p {pid} -L -o pcpu,pmem,pid,tid,time,tname,cmd
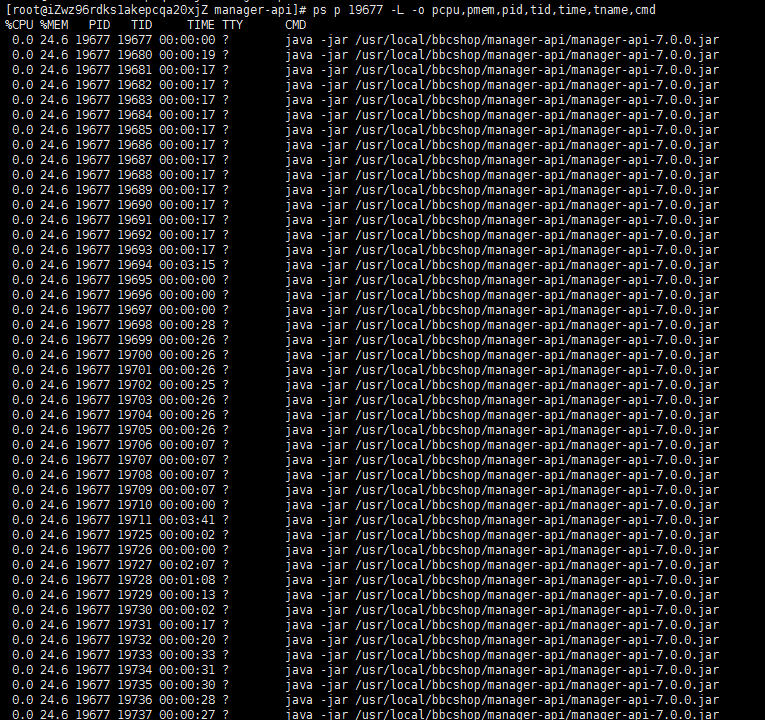
可以看到进程 19677 产生了一百多个线程,一个线程默认占用 1m 空间。考虑是其它原因引起。
如果产生了太大的线程,成千过万,考虑是代码逻辑问题。
4.1,生成 dump 文件
# jmap -dump:format=b,file=dump.hprof {pid}
将 dump.hprof 导出本地,使用 Eclipse Memory Analyzer 进行分析线程和对象。
五,分析 Java 堆详细信息
可以用 jmap 命令查看 Java 堆详细信息,如使用哪种回收器,jvm 参数配置,分代情况等。
$ jmap -heap {pid}
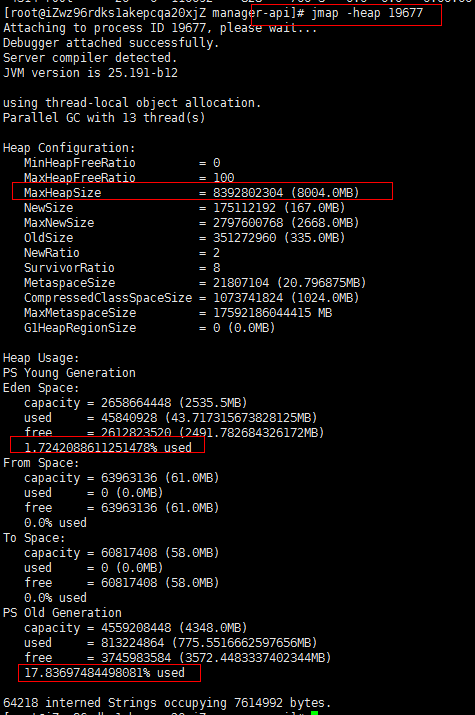
可以看到,这个进程没有设置最大堆内存的信息,默认是服务器内存的 1/4。该进程实际使用的内存并不大,但整个进程占用了8G的内存。这种情况,可以考虑设置初始堆大小 -Xms 和最大堆大小 -Xmx 的值为适当的值。
5.1,分析堆中对象统计信息
如果空间占用率很大,用 jmap -histo 命令分析堆中对象统计信息,包括类、实例数量和合计容量等。
# jmap -histo:live {pid} > histo.log
# head -n 200 histo.log
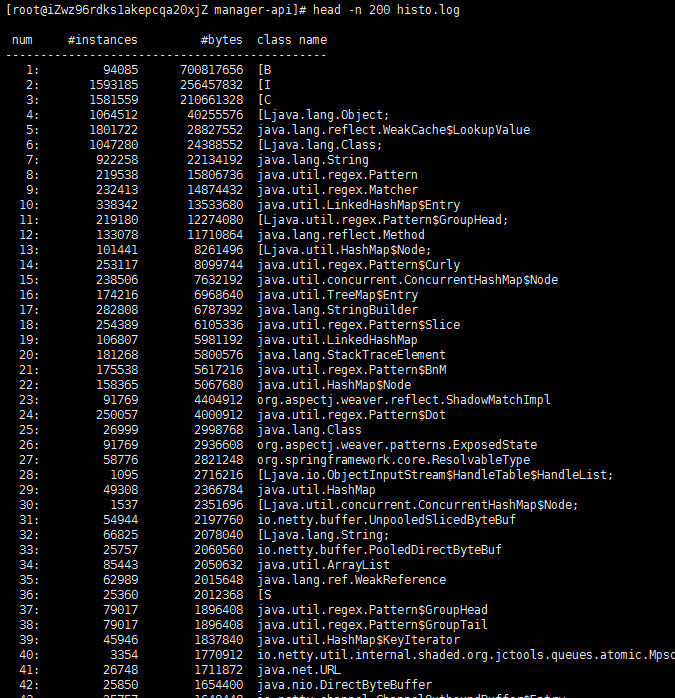
知道了原因,对该服务的 -Xms 和 -Xmx 参数进行优化,重启该服务:
-Xms4g -Xmx4g

可以看到重启后该服务的内存占用降了下来,我们再用 jmap -heap {pid} 命令查看该服务的堆详细信息, -Xms 和 -Xmx 参数有无生效:

六,总结
内存占用过高问题,我们可以先用 top 命令定位占用内存过高的进程,排查该进程的日志打印文件是否过大而占用大量内存;排查该进程是否产生了大量的线程;通过查看对信息分析初始堆大小和最大堆大小的配置是否合理;进程的内存使用率是否过高,通过分析堆中对象统计信息或 dump 文件找出大对象,优化代码。
相关文章:
评论区